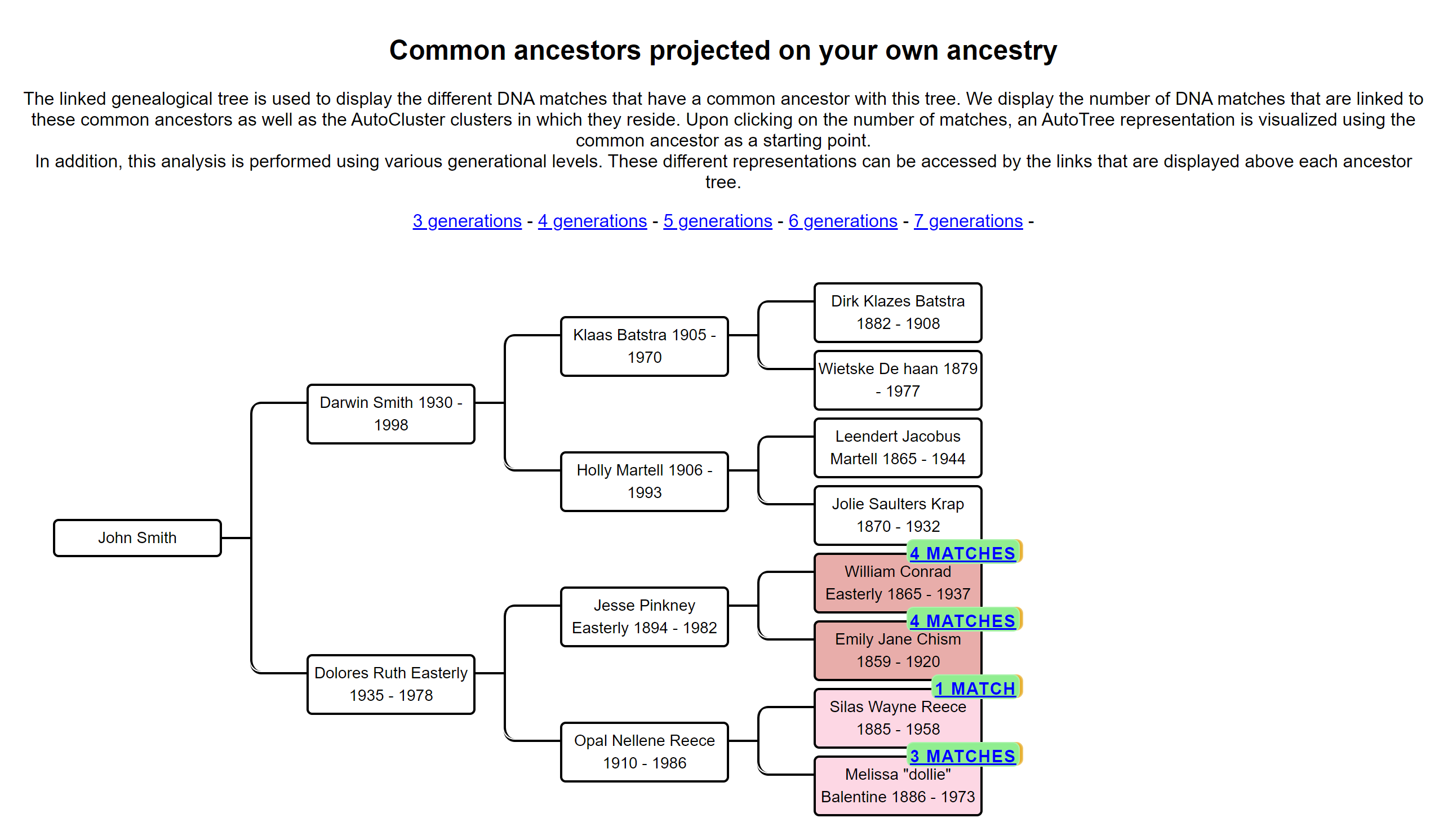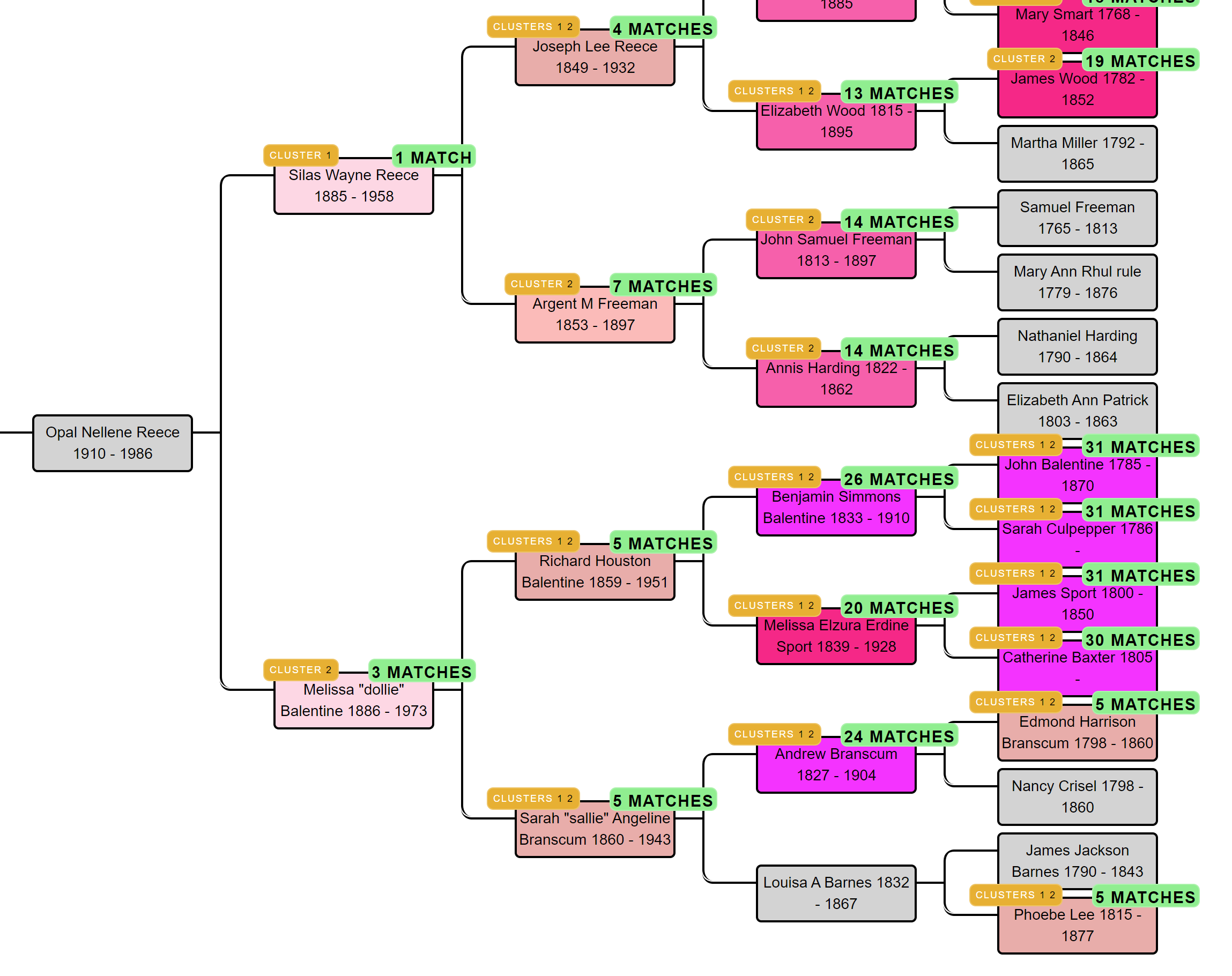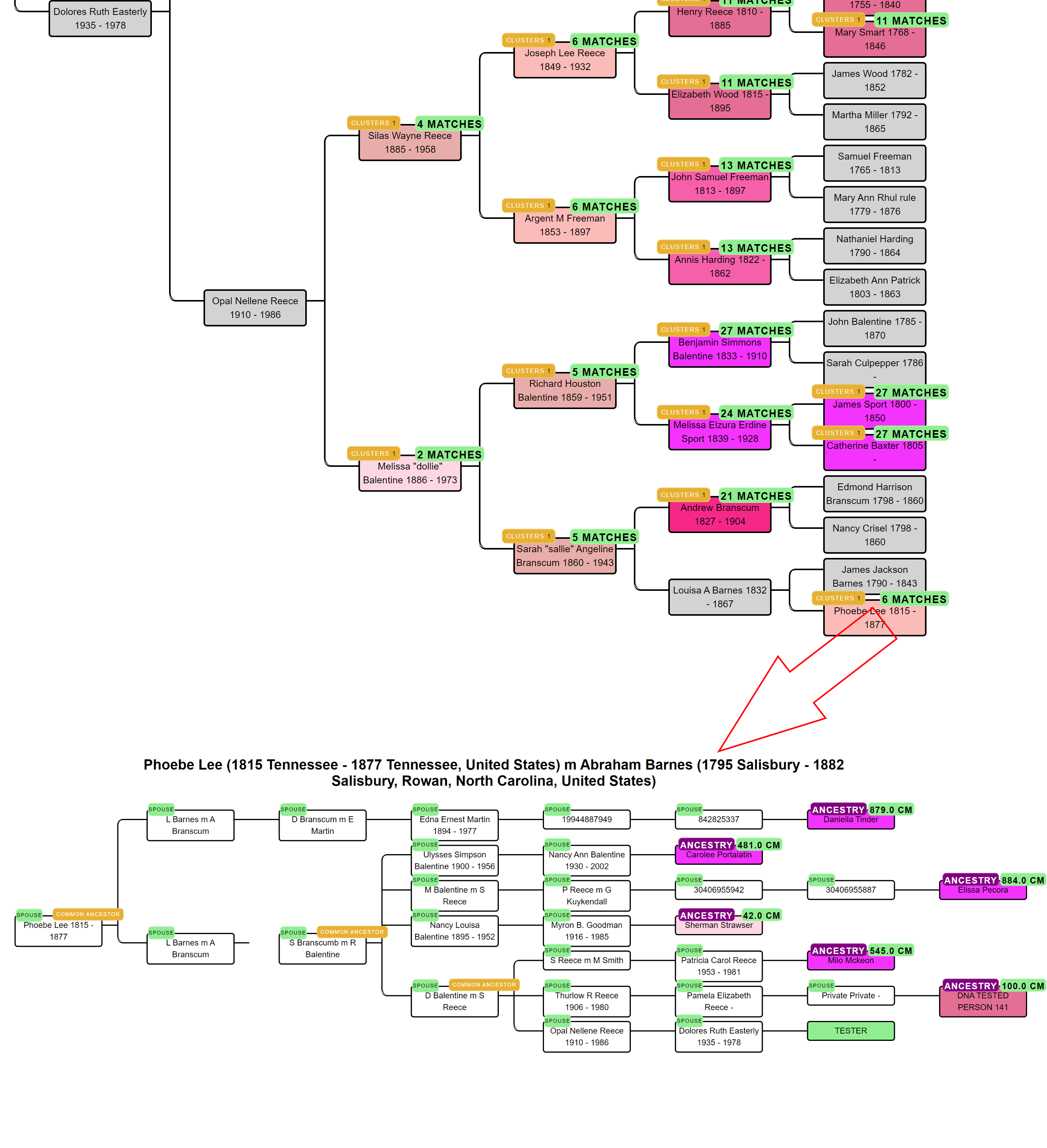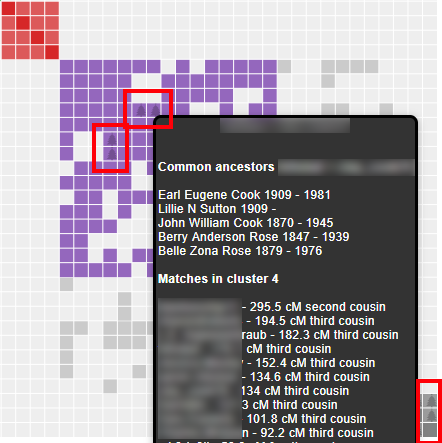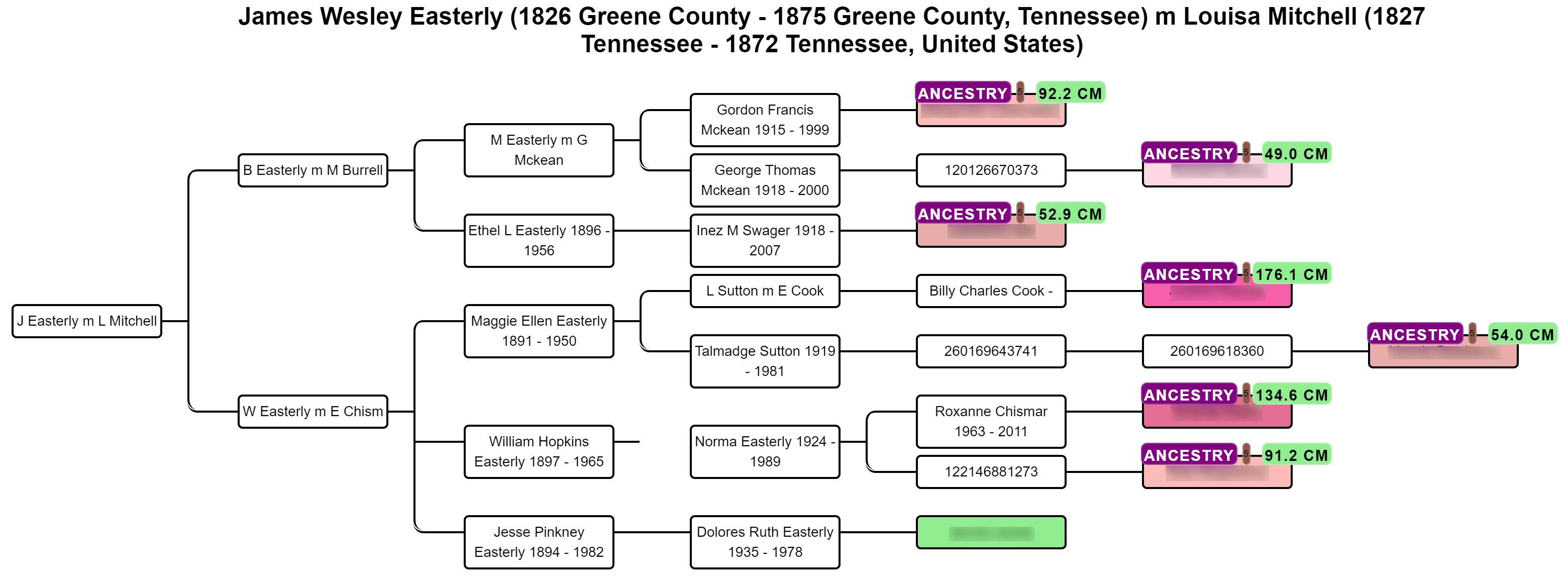
AutoTree concepts
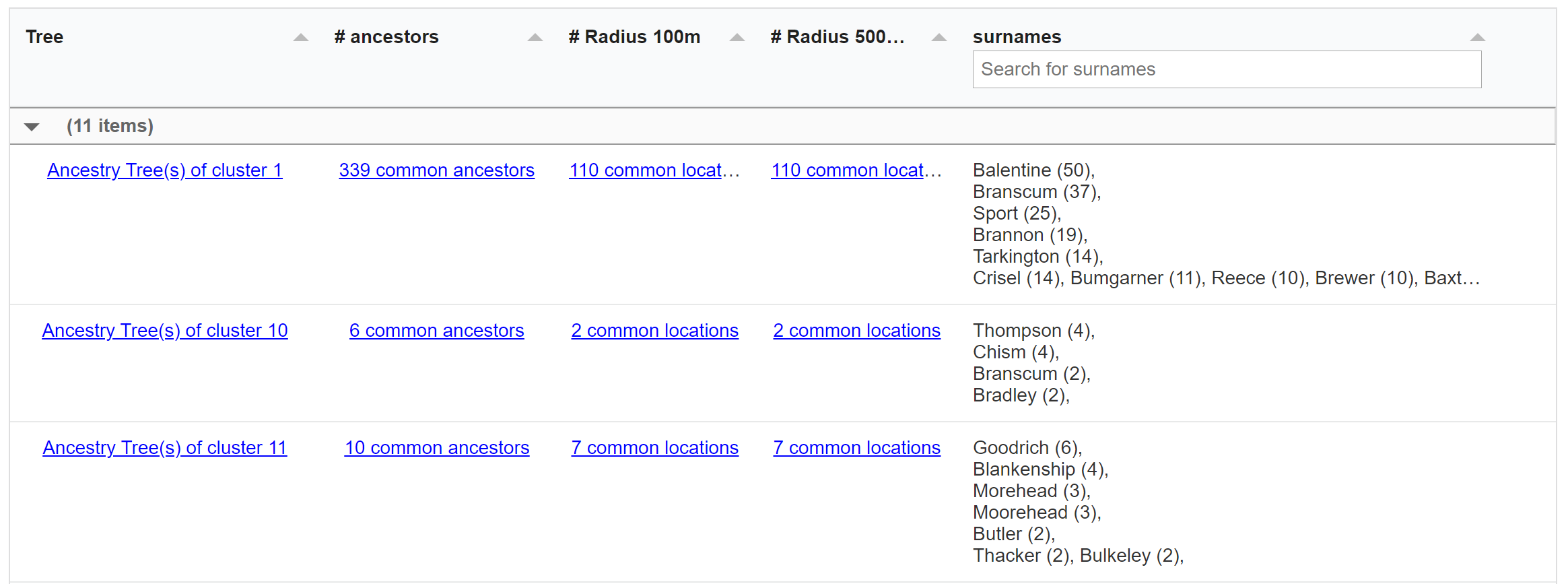
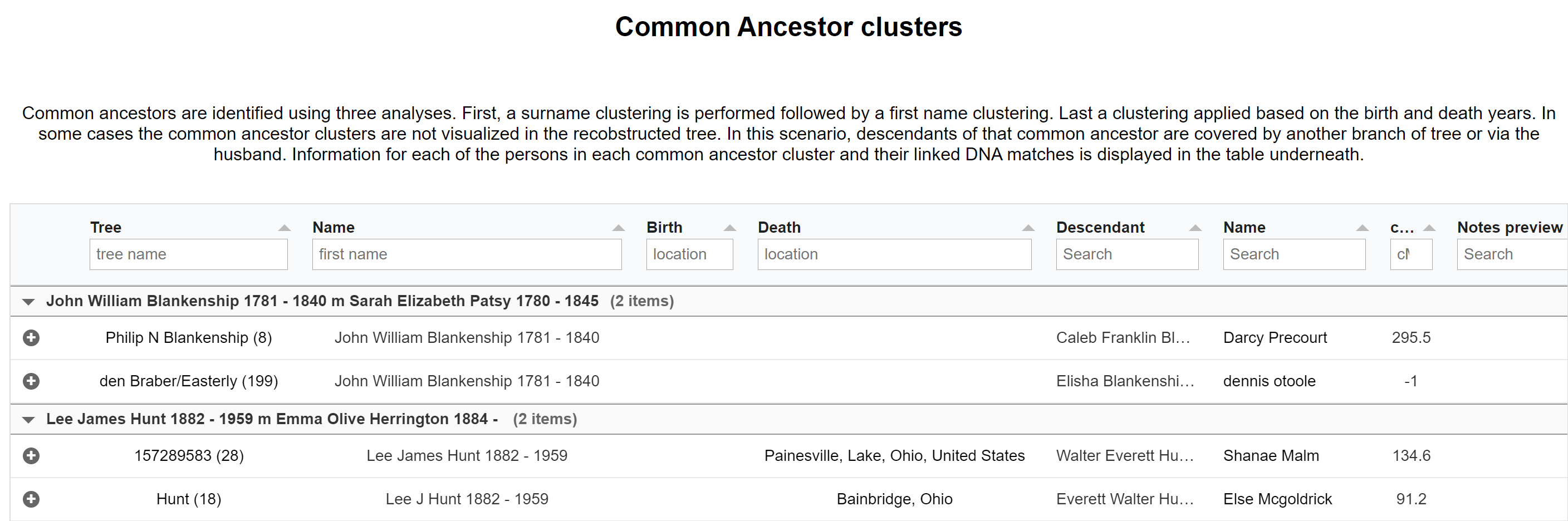
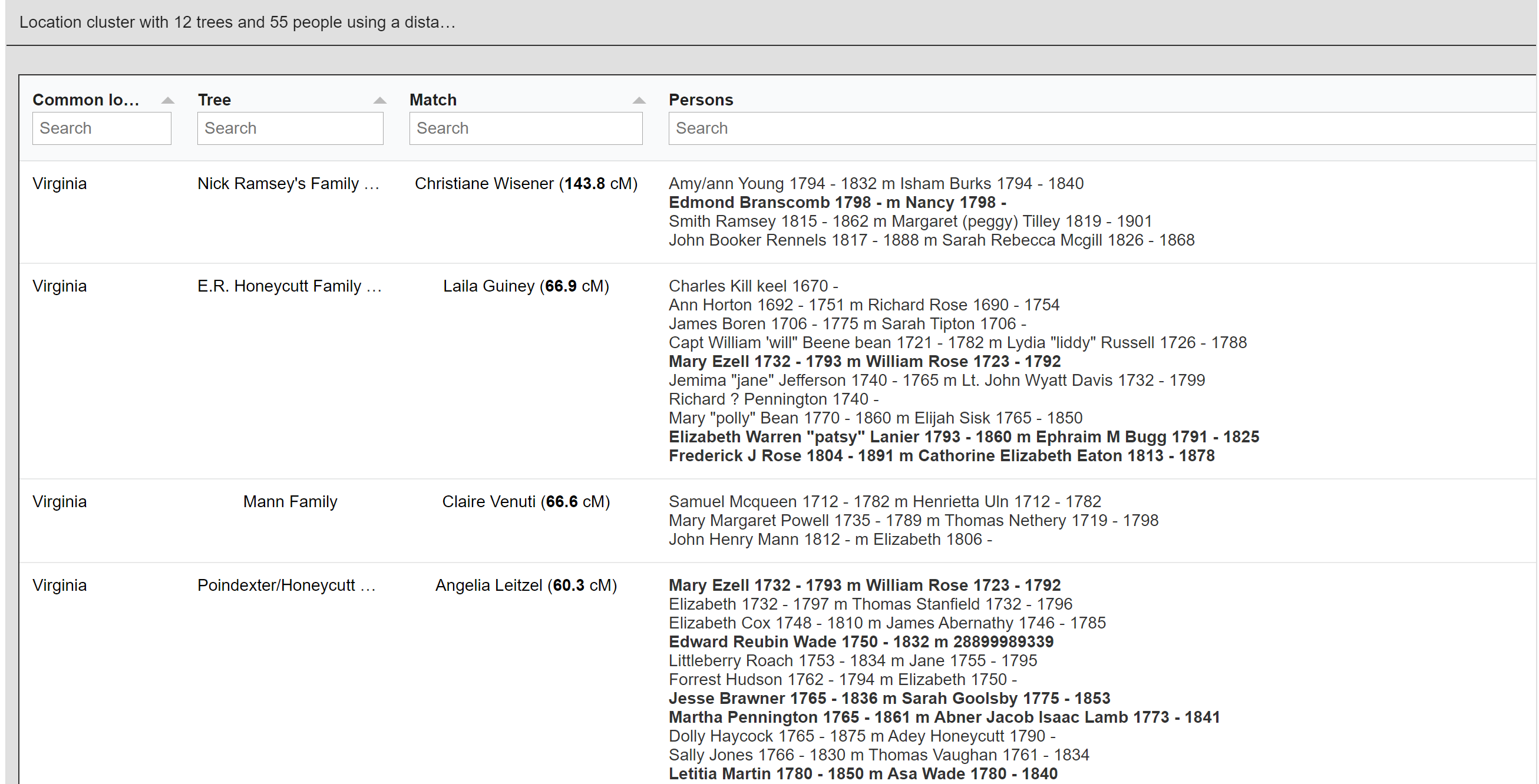
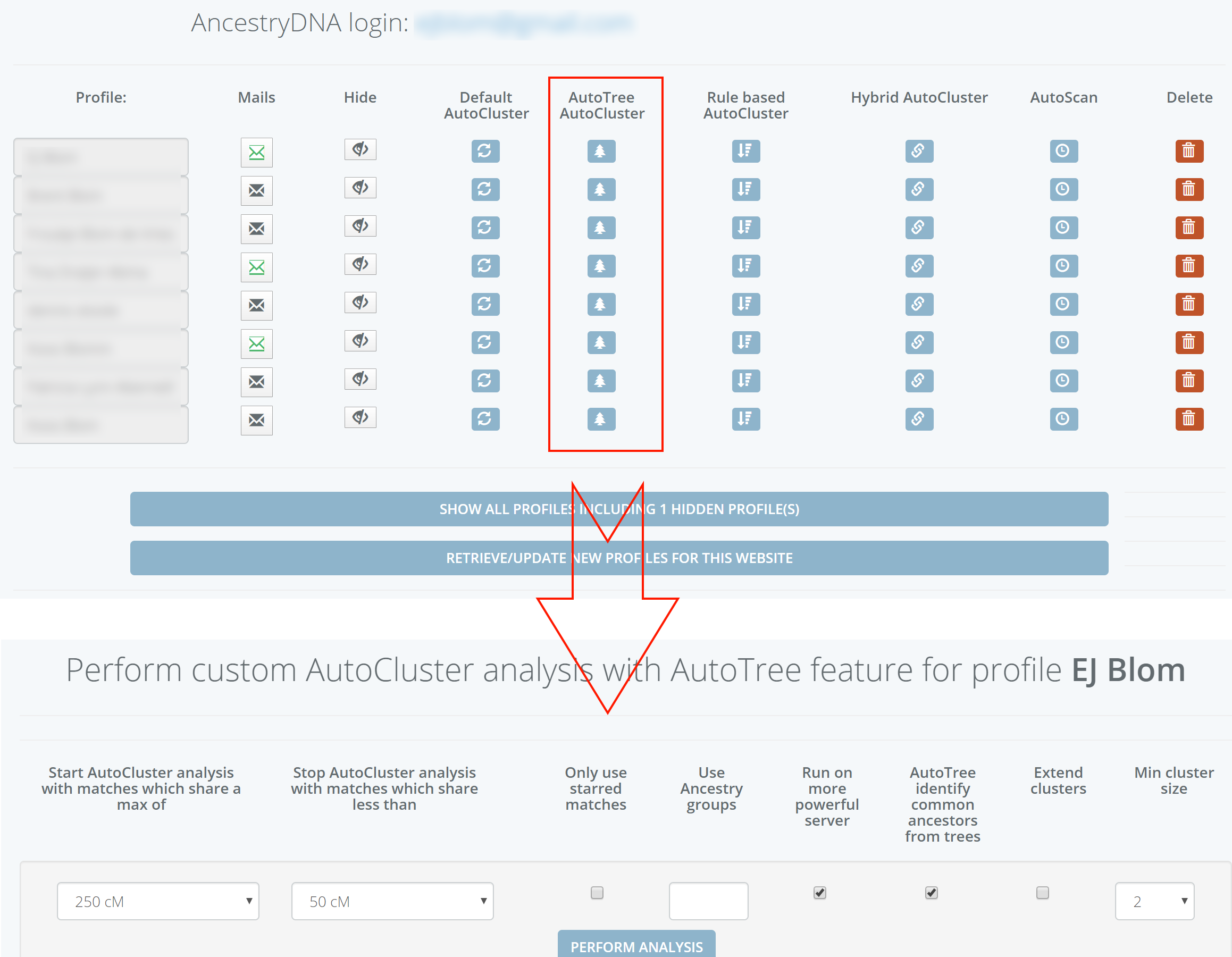
AutoCluster organizes your DNA matches into shared match clusters that likely represent branches of your family. Everyone in a cluster will likely be on the same ancestral line, although the MRCA between any of the matches and between you and any match may vary. The generational level of the clusters may vary as well. One cluster may be your paternal grandmother's branch, while another may be your paternal grandfather's father's branch. By comparing the trees from the members of a certain cluster, we can identify ancestors that are common among those trees. First, we collect the surnames that are present in the trees and create a network using the similarity between surnames. Next, we perform clustering on this network to identify clusters of similar surnames. A similar clustering is performed based on a network using the first names of members of each surname cluster. Our last clustering uses the birth and death years of members of a cluster to find similar persons. As a consequence, initially large clusters (based on the surnames) are divided up into smaller clusters using the first name and birth/death year clustering.
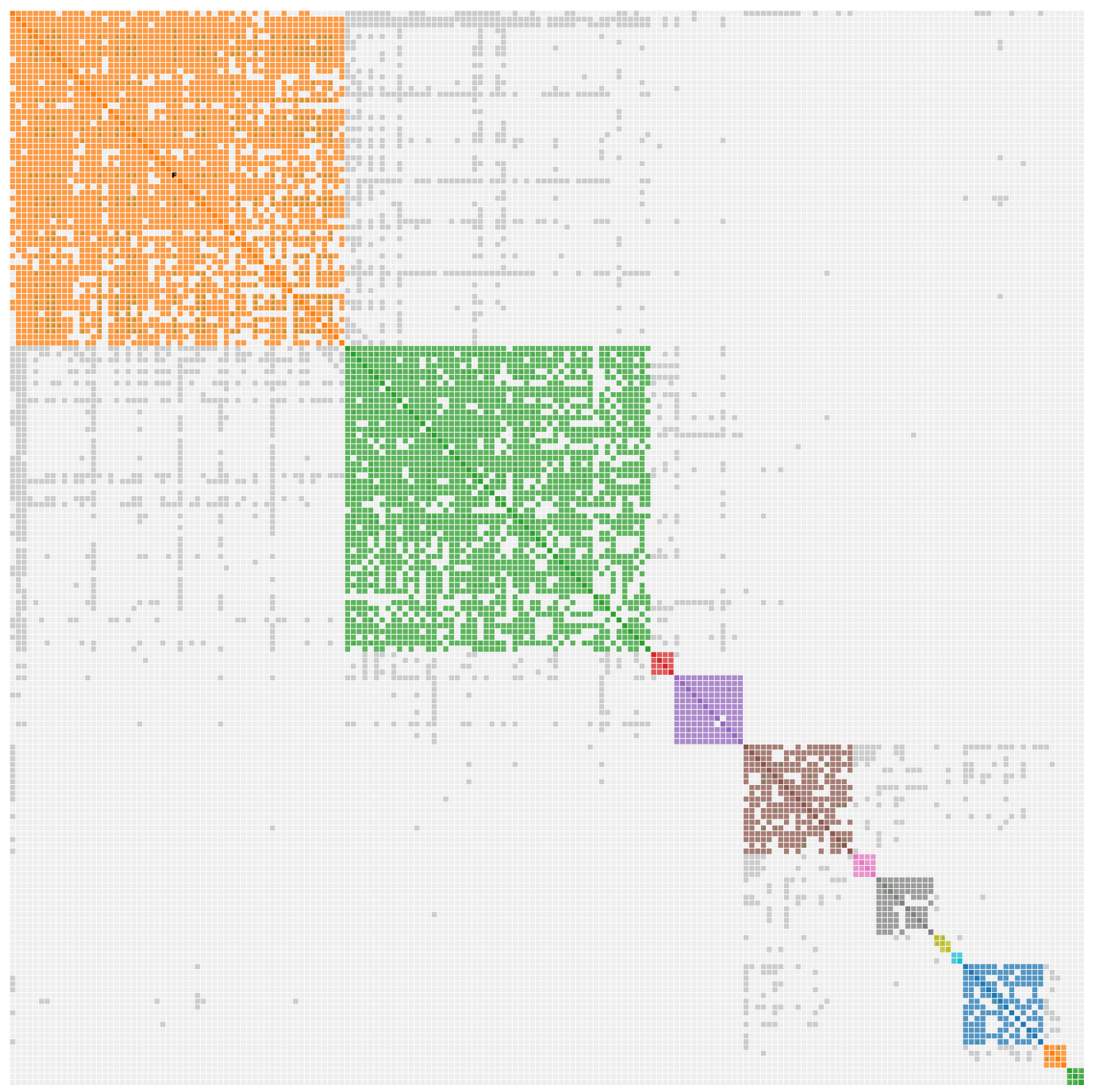
AutoTree concepts
AutoCluster organizes your DNA matches into shared match clusters that likely represent branches of your family. Everyone in a cluster will likely be on the same ancestral line, although the MRCA between any of the matches and between you and any match may vary. The generational level of the clusters may vary as well. One cluster may be your paternal grandmother's branch, while another may be your paternal grandfather's father's branch. By comparing the trees from the members of a certain cluster, we can identify ancestors that are common among those trees. First, we collect the surnames that are present in the trees and create a network using the similarity between surnames. Next, we perform clustering on this network to identify clusters of similar surnames. A similar clustering is performed based on a network using the first names of members of each surname cluster. Our last clustering uses the birth and death years of members of a cluster to find similar persons. As a consequence, initially large clusters (based on the surnames) are divided up into smaller clusters using the first name and birth/death year clustering.